If there is one type of content strictly banned and monitored across every platform on the internet, it is the CSAM (Child Sexual Abuse Material). For this reason, those who seek to consume such content must turn to very specific channels to access it.
Across mainstream platforms like social media, websites on the clear web, and even apps like Telegram—which is often seen as an open and convenient space for cybercriminals, or at least it was before Durov had a “talk” in Paris—strict policies are in place to swiftly detect and remove CSAM-related materials. This is why most of this content is typically found on the Dark Web.
The fact that is hosted there presents two primary challenges for investigators. The first is the peer-to-peer nature of the Dark Web networks, like Tor. As many of you may already know, Tor employs onion routing, where user data is encrypted in multiple layers and relayed through a series of nodes, each decrypting only its specific layer. Unless we had absolute control over every node in the circuit used by the specific user (an absolute dystopia), it would be virtually impossible to trace back to the user’s original IP address.
You could also try to build a signature based on the differences of that user’s Tor Browser (time zone, doesn’t answer certain JavaScript queries, doesn’t answer certain history requests, etc) to make a more unique profile. But this still doesn’t break the anonymity in any way.
The second challenge, while not directly tied to the Dark Web itself, lies in the ease and anonymity of registering and logging into these websites. As you can see in the following image, nearly all the sites I’ve analyzed only require a username and password. There’s no verification process, no email required, no additional data of any kind. Nothing.
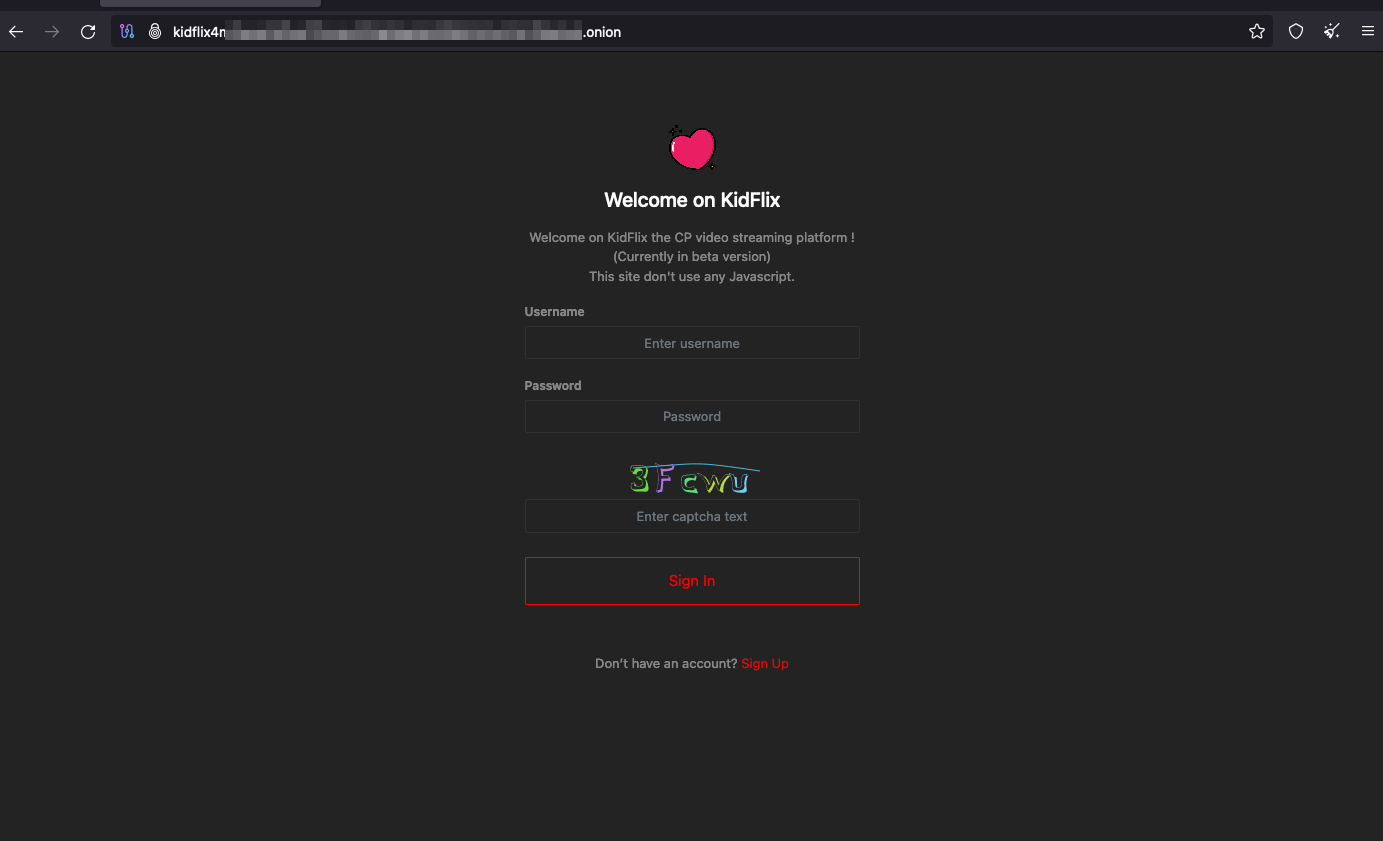
This means that anyone can create one or multiple accounts using entirely random characters or highly generic usernames with absolutely no connection to their real identity.
For these reasons, the initial landscape for an investigator can be incredibly discouraging, making it nearly impossible to identify either the creators or the consumers of these sites. And this is exactly what we will cover in this post, an alternative that will habilitate you to profile these guys.
Stealer Logs
I guess by now, most of you have probably heard about Stealer Logs. This is essentially data generated by a type of malware known as InfoStealers. The reason we’ve seen such a rise in their popularity over the last 4–5 years is largely due to the massive commercialization of InfoStealers as MaaS (Malware-as-a-Service). Take Redline and Racoon as examples.
These—I would even call them companies— allow you to purchase a relatively cheap license and gain access to a ready to use command-and-control portal. From there, all you need to do is focus on infecting users and gather the data that is coming from the infected devices. Even thought infection campaigns can vary a lot, the majority of infections I’ve seen from Stealers come through pirated content, like media content, games or programs. Yeah, the typical —“🔧HOW TO DOWNLOAD & USE PHOTOSHOP ON PC / LAPTOP FOR FREE🔥(2024)”— we all know.
This whole explosion of InfoStealers has also (of course) led to a ton of garbage floating around. You’ve got reused logs, incomplete datasets, and endless Telegram channels sharing and resharing the same data over and over. But with the right tools, or some patience and cleaning up, we can actually make good use of this mess. Once it’s filtered and organized, this info becomes super effective for getting real work done.
What information do Stealers generate
Let me first say, it may depend on the Stealer. Not all of them extract the same data from the devices. But, we do have some consistencies. The most important thing for us, is that it usually gathers credentials and wallets saved on the browser, Cookies, sometimes the files of the system, and very important, hardware data. Will paste some images here so you can see how this data looks.


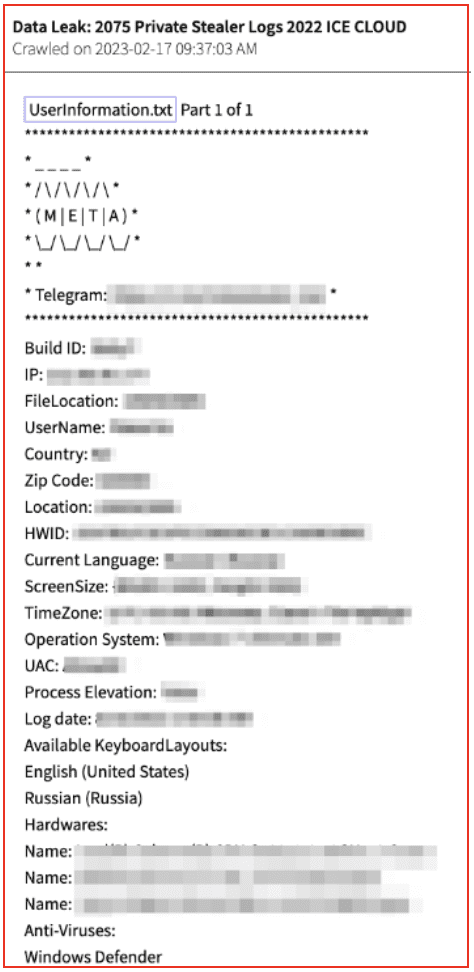
Mapping out each CSAM site
Alright, enough with the introductions. The starting point of this investigation was a list of domains where we knew CSAM was being shared. All we had were the Onion domains of these sites. As you might remember, one of the pieces of information contained in Stealer Logs are login credentials. By searching for the domain, we can map out all the users who might have saved credentials for that site. And that’s exactly what I did for every single site of the list. Results? Thousands of single lines.
Even this being a good start, this data still has a very low relevance for us. I mean, check some of the usernames we found:

We need something more, as in the majority of cases, these usernames are not worth a dime. If you remember, the other piece of data found on Stealers were Hardware data, which includes, besides other stuff, the unique device serial number. If we now relate each one of these lines with usernames, to the specific device it was extracted from, we are able to create a picture of the devices registered on those specific sites.
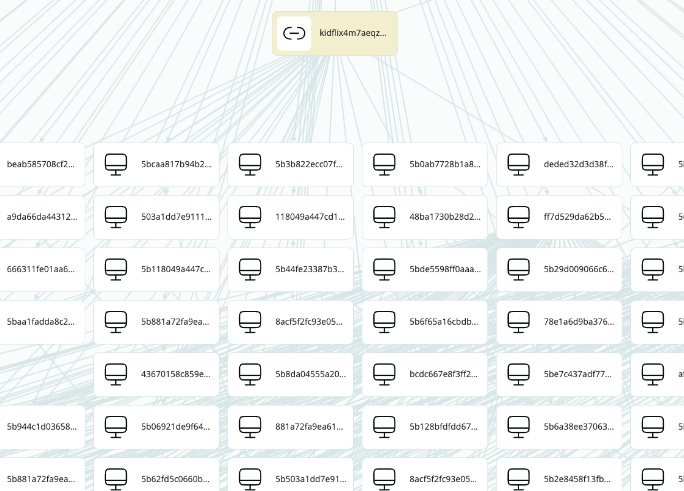
Now that we have the serial numbers, we can run another search through our database of Stealer Logs, this time using the device serial numbers as the key. The results we get now are no longer just a random list of usernames on a website. Instead, we get a complete map of each infected computer register on that site.
For example, our guy “HellBoy984” is no longer just a random username. Now we can see multiple associated emails, phones, IDs on some .gov sites from his country, bank creds and whatever may have been extracted from his PC by the Stealer. And now you are set and ready to start profiling these guys, and enjoy the hunt.

Profiling a CSAM consumer
A lot of the times, data found in Stealerlogs can be enough to profile a user, and you don’t need to actually go deeper than that. But in some cases, extracting these identifiers and looking up for profiles and other related data could show us some intriguing/valuable stuff. This one I will show you, is a good example of that.
We start with the same workflow I showed you before. Search by the site URL (in this case from the site “amorzinho”, one of the biggest in Brazil and internationally), map the users, extract the associated device serial numbers of each of them, and then start to work on each of the devices.
The fake identity
I’ve cleared the data on the screenshot, but you can see from the credentials I found on this specific user, who called himself “katy” on the CSAM site, we gather several emails, where two of them hold special value.
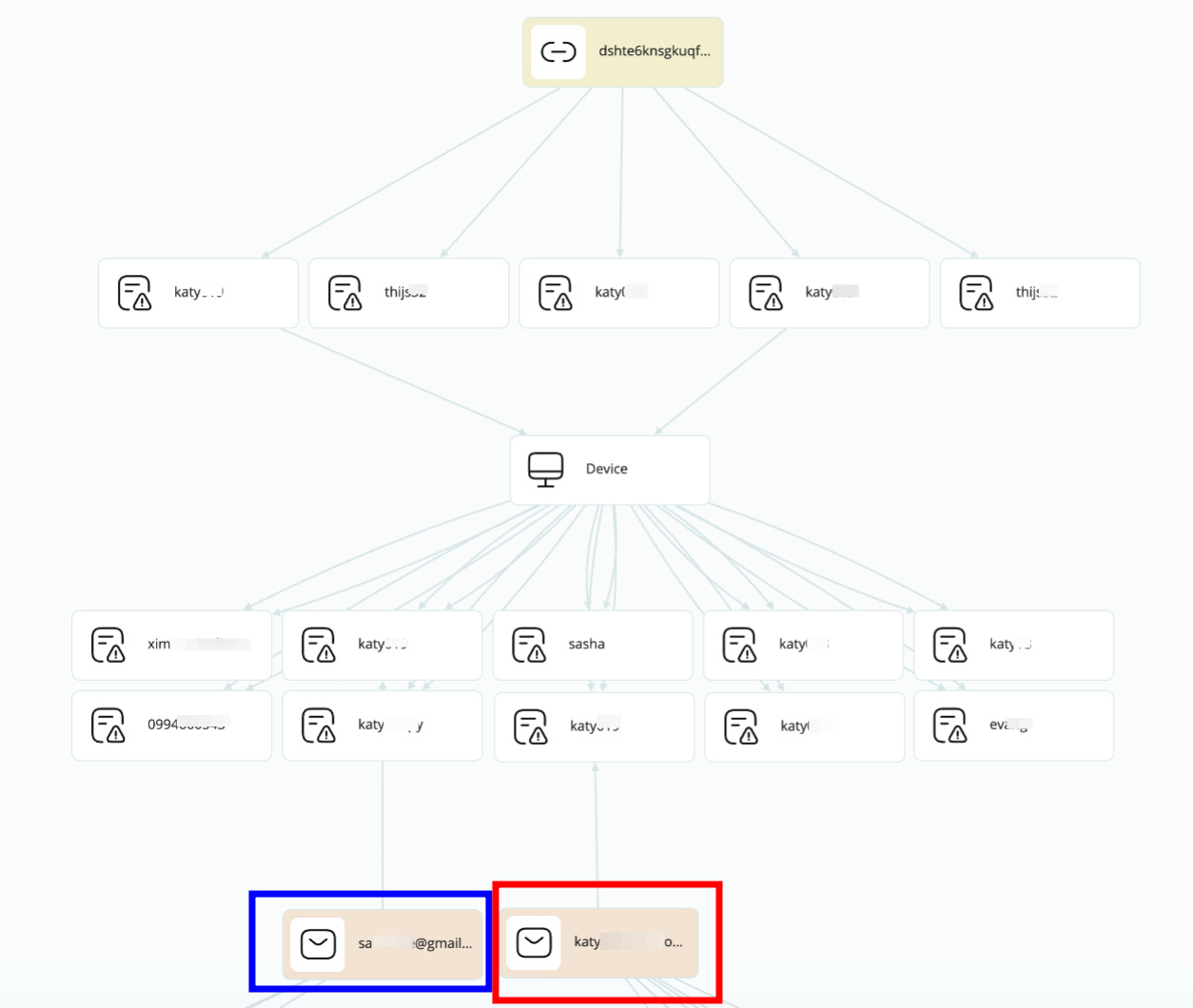
The email on the left is his main personal one, attached to all his real life activity. The one on the right, his main one for his non-Orthodox online activity. Let’s start with the second one.
With an initial bulk search, we gather some profiles that hold very low importance, like a Gravatar one, or empty google account. But what we did find was some registries on leaked data (the black eyes you see on the picture, from SL ISE on Crimewall). There we are able to extract an IP from Paraguay, and a facebook ID attached to the email.
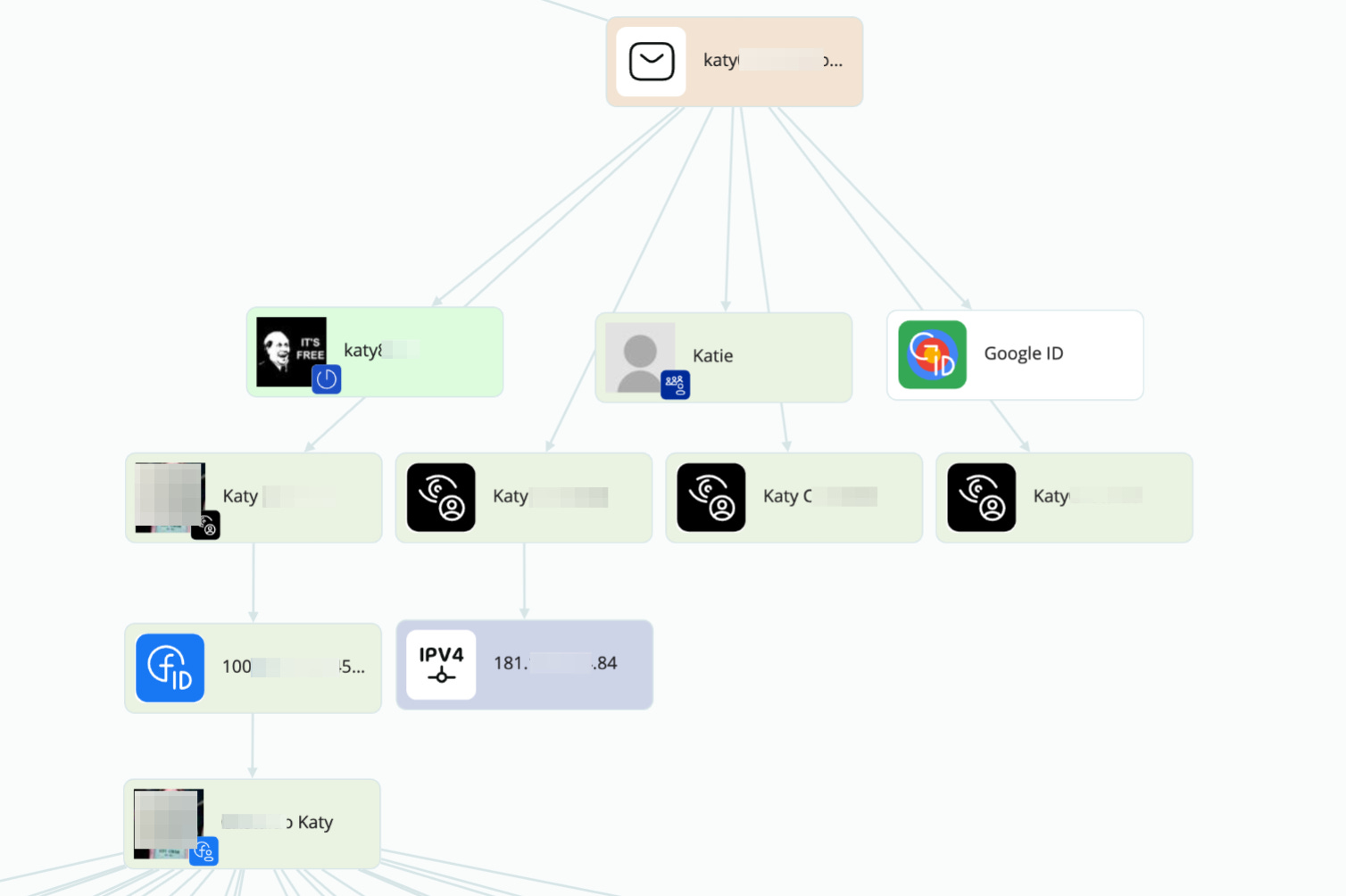
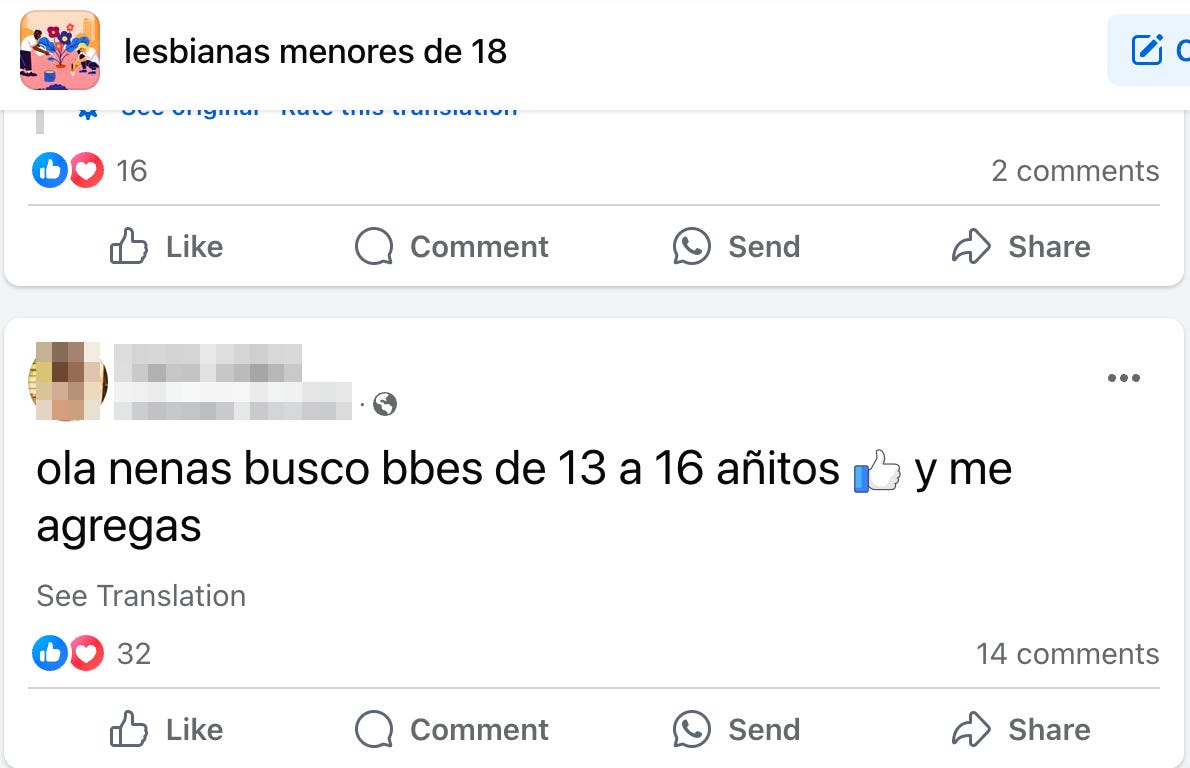
If we take a closer look at the information extracted from this Facebook profile, it quickly becomes clear what this fake identity is being used to contact minors through social media. As shown in the photo, this person is pretending to be a lesbian girl and is part of several groups, such as “lesbian minors under 18,” “cute little ones,” and others of a similar kind.

Although not everyone in these groups is a sexual predator, it’s clear that these spaces contribute to the vulnerability minors can face online. And it’s obvious this doesn’t just happen on Facebook. We’ve seen how, for example, platforms like Discord have absolutely alarming rates of grooming.
But anyway, getting back to our case, you can see by the posts on these groups, “katy” is not the only one grooming minors there.
The real identity
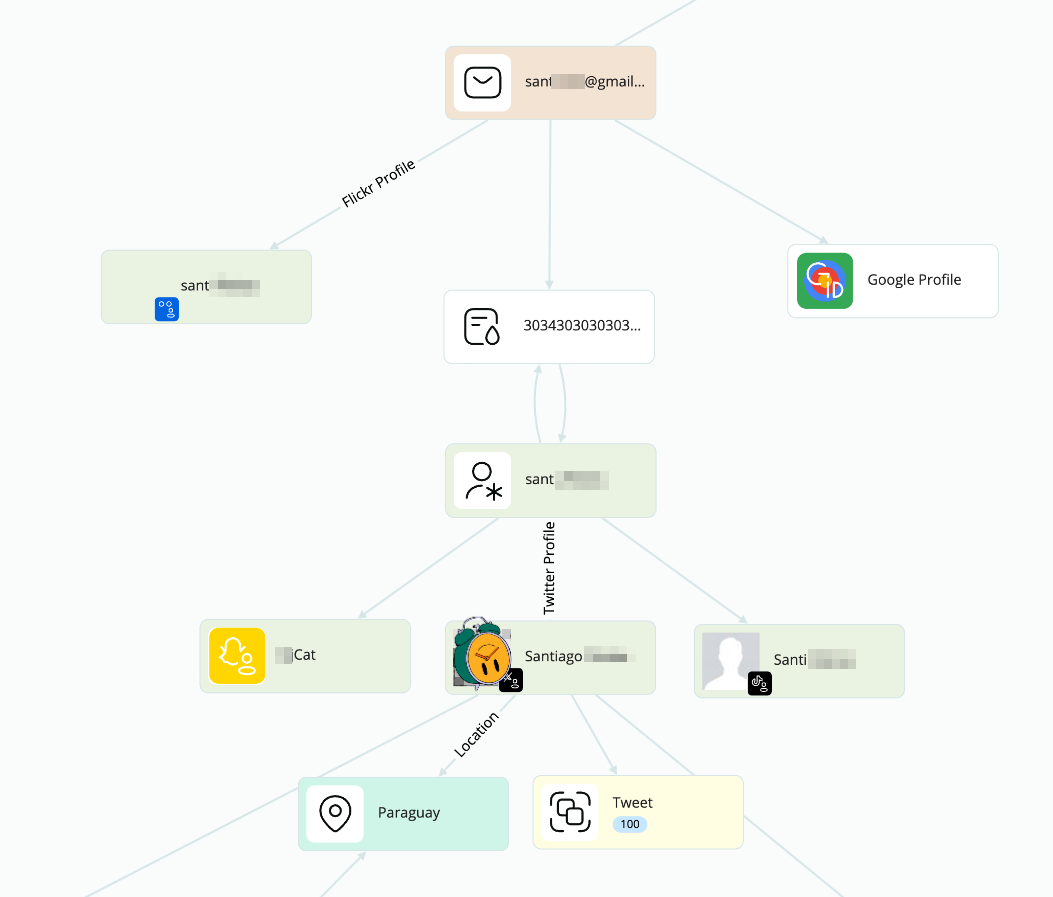
Enough for now, let’s see who this guy is. Doing a search on the other email we had, and cleaning up some of the results, we see one relevant leak from Taringa. On it, a username that points out directly to a Twitter (X) profile. Remember the location of the IP of Katy? Exactly, Paraguay.
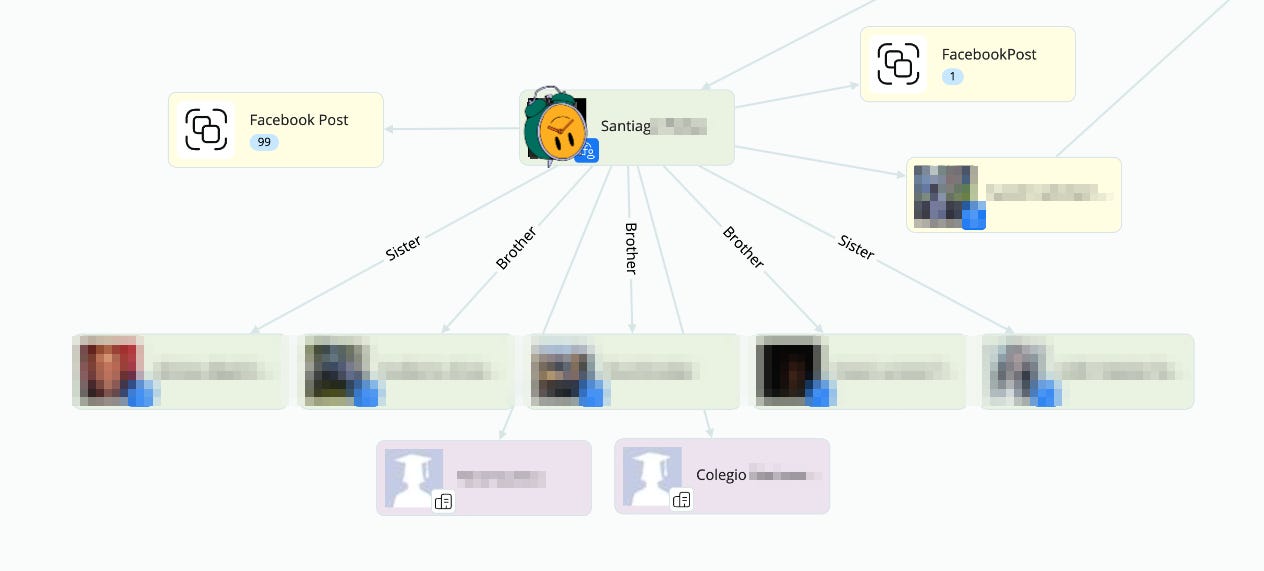
Unfortunately, I cannot get into too much detail from here, but with the help of some facial recognition on Crimewall, we are able to get his profiles on Facebook, Instagram… with data of where he studied, who his family is, where he has been traveling to, when he graduated… Let me show you a bit of it, redacted.
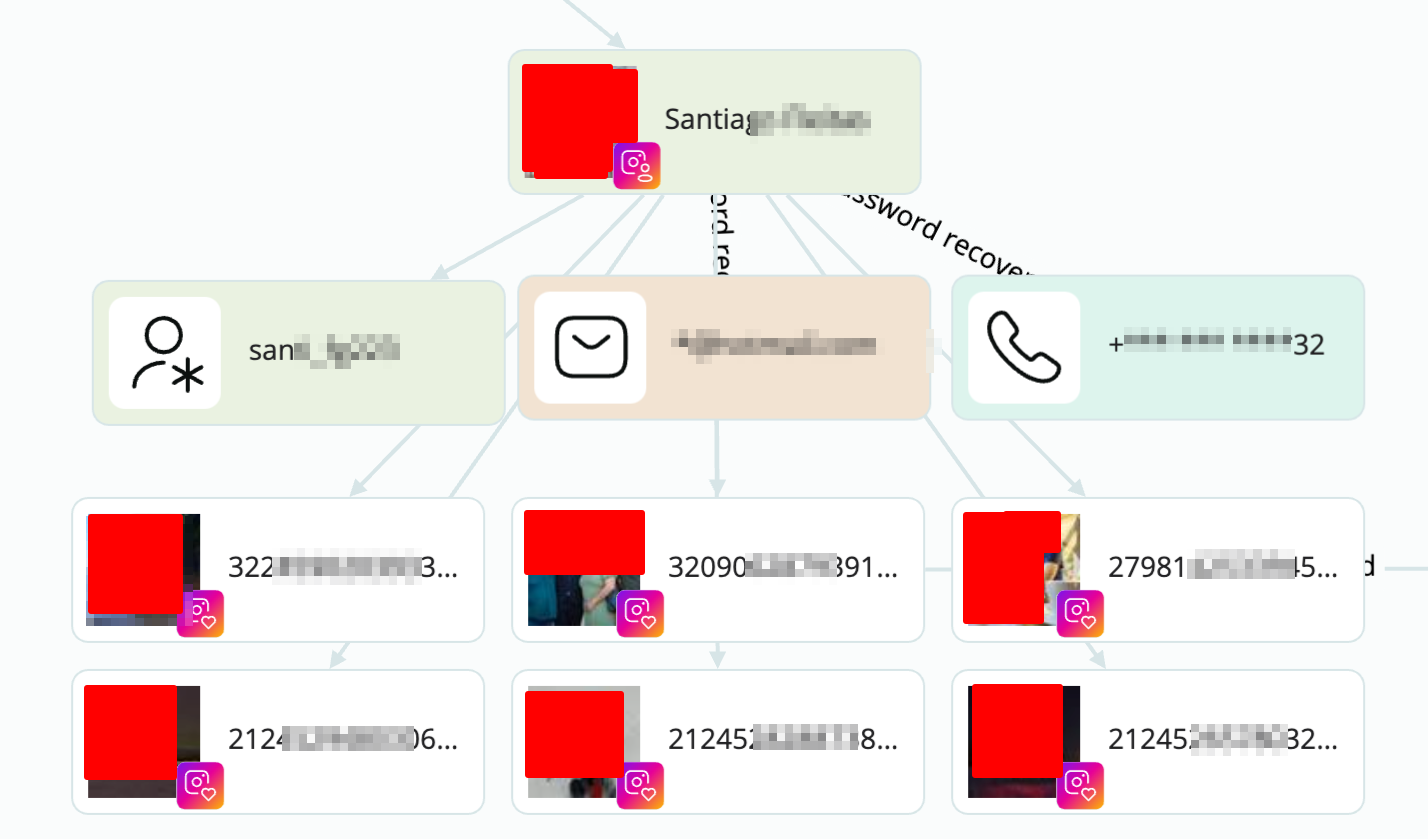
There is more, and this is only one of the devices that we got from that site. Make your own conclusions of the power we got on our hands here 🙂
Finale
What I’m presenting to you today is a methodology. A methodology that can break the anonymity of many actors who, until now, we couldn’t even begin to gather information about, or could only do so with great difficulty. It is a reverse technique, instead of starting from the individual to get to the infraestructure, we start from the infraestructure to get to the individuals.
Of course, as many of you might already be thinking, this isn’t a foolproof technique. For starters, it requires that the actor, the person you’re investigating, has already been infected beforehand.
Let’s take, for example, these child pornography websites. It’s obvious that when we map out these sites and the devices connected registered on them, we’re not mapping their entire database. We’re mapping the ones that have been infected. However, in many investigations, all we need is to dip our toe in just enough for the house of cards to start wobbling and eventually collapse.
And if, while reading this, you’ve been drawing your own conclusions and thinking about how you could apply this to your own cases, you’ll have realized that this isn’t just a methodology for combating, for example, CSAM content on the internet. It’s a methodology that can be extrapolated to any case where the starting points are a domain, a URL, or other pieces of information that can be found in stealer logs.